摘要 一晃时间过的真快,距离上次更新博客已经将近10天了,这十天来也没闲着,回家终于把杀千刀的科目三过了,再也不用看到教练那张凶神恶煞的脸。前段时间四六级考试成绩公布了,小伙伴们是不是都第一时间忙着去查自己的成绩,相信有很多小伙伴跟我一样苦逼,幸幸苦苦复习了好长时间,查成绩的时候却忘了自己的准考证号(温馨提示:以后考试之前一定要记得把准考证拍一张存起来)。在网上试过无数种找回办法后,我彻底绝望了。既然别人不靠谱,咱就靠自己,经过两天的努力之后,终于成功的找回了准考证号。这篇博客主要来介绍解决这个问题的一些方法和思路。

文章概览
基本思路
对于查询四六级成绩来说,官方的查询入口有学信网和中国教育考试网,查询成绩需要提交的数据包括准考证号、姓名和验证码。要想查询到成绩,最简单的办法就是手工枚举准考证号,一个一个的尝试。我们知道四六级准考证的组成如下所示(第10位表示类别,四级是1,六级是2):
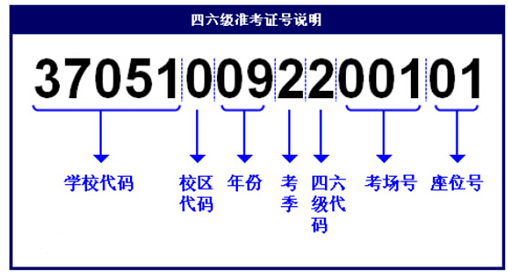
也就是说对于在同在一个考点的人来说前十位都是一致的(四级和六级不同),后面五位分别表示考场号和座位号(座位号从01到30),在我们忘记了考场号和座位号的情况下,我们至少要手工枚举几千次才有可能查询到成绩,这个工作难度可想而知。那如果我们不采用手工的方式进行枚举,而采用程序自动进行枚举呢?通过程序枚举准考证号不是什么问题,但是查询参数中包含验证码,现在需要解决地就是如何识别验证码。对于验证码地识别问题,我们可以利用机器学习的相关算法,建立识别模型,再利用识别模型来进行识别验证码。对于学信网和中国教育考试网两个网站,它们采用的验证码不同,学信网的验证码比较复杂,包含汉字等特殊字符,识别难度大,而中国教育考试网的验证码相对来说比较常规,识别难度相对小一点,本文的查询操作都是基于后者而言的。
那么我们解决问题地大致思路就是:首先我们要获取大量的验证码数据,然后选择算法训练识别验证码的模型,最后通过重复识别查询页面的验证码,提交查询数据,分析响应数据来获得最终的结果。
训练模型
获取训练数据
通过抓取请求相应过程中的数据包,我们可以得到获取验证码的地址。
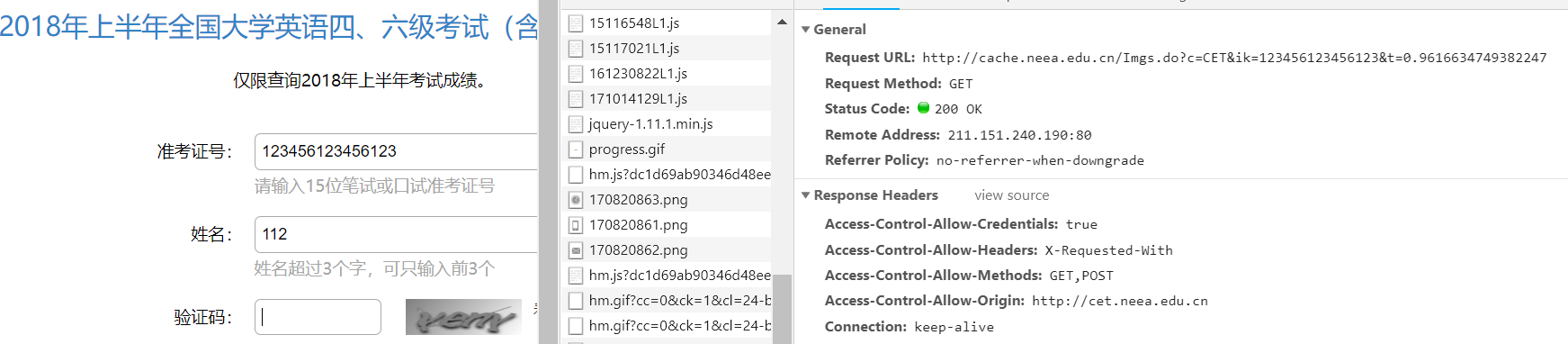
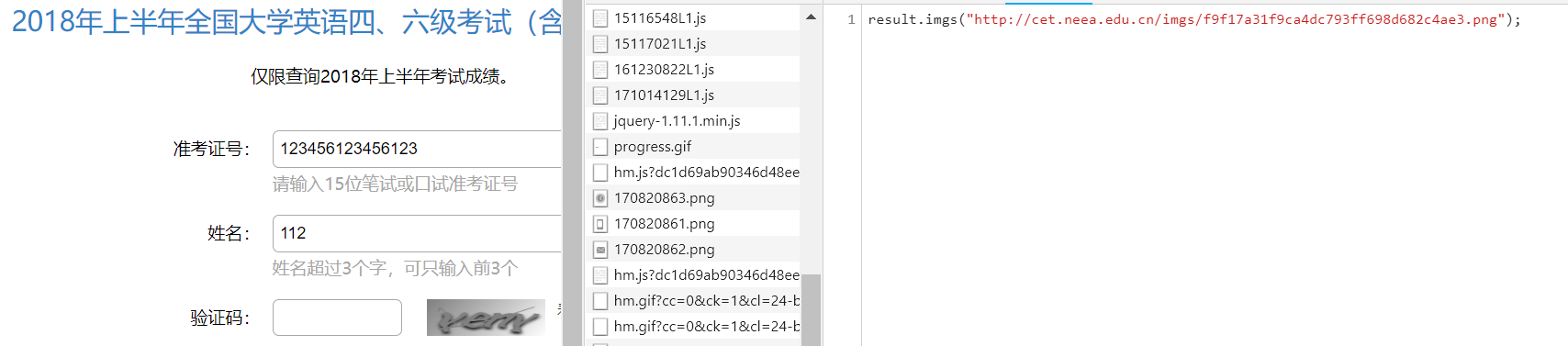
其中ik表示准考证号,我们可以随便填一个,t表示时间戳(这个可以不用管),我们可以不断地向这个地址发送请求,服务器的响应结果即为验证码的地址,我们再向获取到的验证码的地址发送请求,就可以得到验证码。
具体代码如下所示(该项目的所有代码都可以在我的Github中找到):
1 | # 获取验证码 |
处理数据
获取到一定数量的验证码图片后(大概需要100多张,收集的图片越多越好,之后我们会讲到一种快速收集和标注验证码的方法),接下来我们需要对获取到的验证码进行相应的处理。因为对于验证码的识别,我们一般采取监督学习的算法训练模型,所以首先要对获取到的验证码进行标注,即将验证码图片的文件名改为验证码对应的数字和字母组合,这一步必须要人工进行操作。然后,为了提高验证码识别的准确率,训练更好的识别模型,我们需要对验证码图片进行相应的处理,如灰度处理、二值化、降噪。经过这些手段处理后的验证码更能体现出图片本身的特征,同时也减小了训练模型时的计算量,具体代码如下所示。
1 | # 灰度处理,二值化(降噪部分的代码去掉了,效果不是太理想) |
下面我们要对验证码进行分割,因为在识别的时候,我们是识别单个的数字或字母,所以我们要将验证码进行切分,提取出每个字符对应的区域,切割后的每张图片大小一致。
1 | # 图片分割,参数img_split_start指定起始位置,参数img_split_width指定切割图片宽度 |
图片切割完成后,数据处理的最后一步是将切割后的图片转化为numpy array的形式。
1 | # 将Image对象转换为array_list |
以上这些操作大家可以在我的GitHub的项目文件中通过preprocessing()、make_train_data()和img_to_array()三个函数实现。
生成模型
生成模型主要用到的就是sklearn机器学习库中相关的算法,验证码识别属于分类任务,对于分类任务我们可以采用K近邻、支持向量机、决策树和神经网络等算法,这里我们采用的是支持向量机。
1 | # 训练模型 |
模型训练好之后,将模型对象存储在model.pkl文件中,需要识别验证码时,只需要读取model.pkl文件即可获得识别模型,不需要再次训练。
查询操作
发送请求
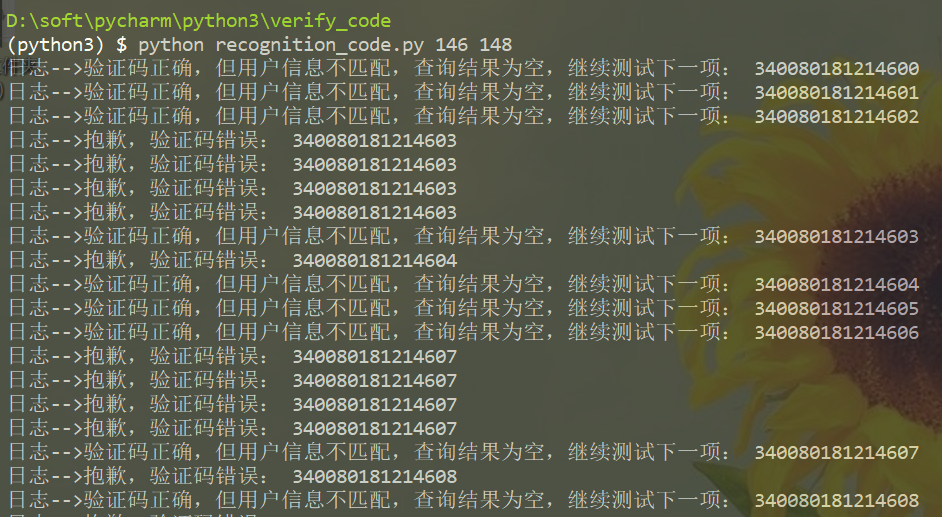
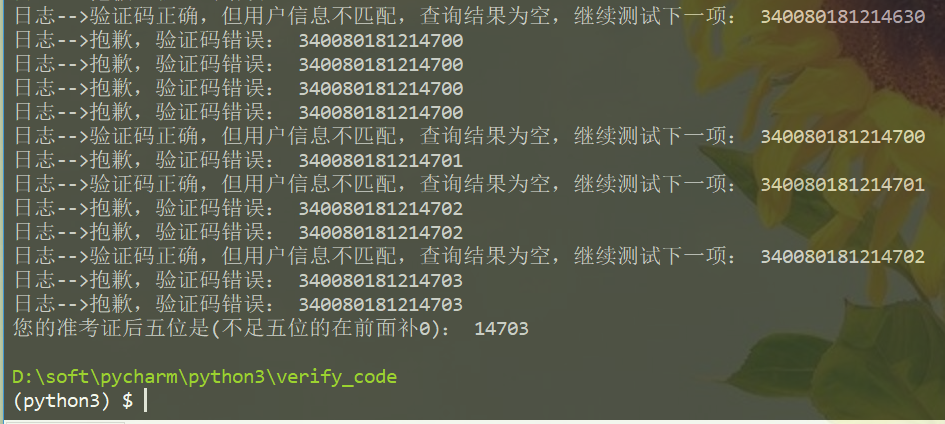
模型训练好之后,我们就可以进行查询操作了。这一阶段的大致思路是,先获取查询页面的验证码,通过识别模型进行识别,然后再向服务器提交请求参数,包括枚举的准考证号、姓名和验证码。如果服务器返回验证码错误,则重复以上操作。如果服务器返回查询结果为空则说明验证码正确,但是准考证号和姓名不一致,此时可以枚举下一个准考证号,重复操作一直到获得正确结果为止。
由于一开始我们训练模型时使用的训练数据量很小,所以该识别模型识别的准确率比较低,那么如何提高模型识别的准确率呢。最好的办法就是增大训练数据的数量,训练新的模型。这里提供一个更快更方便获取训练数据的方法,在发送请求的代码中,我们加入两行代码(倒数第三行和倒数第二行),该代码的作用时将识别正确的验证码加入到训练数据的文件夹中,并且会自动进行标注,可以通过该方式一边查询,一边收集大量的训练数据。我的项目中,一开始手工标注的验证码有200张,训练模型后采用这种方式自动收集了1600多张验证码,然后利用所有的训练数据重新建立模型,识别的准确率提高了30%。(但是这样的做法存在一个过拟合的问腿,训练模型对于类似于一开始200张验证码的图片的识别准确率比较高,而对于其他类型的图片识别的准确率比较低。不过这个问题对于我们找回准考证号影响不大,提高准确率最好的就是一开始手工标注更多的验证码)
1 | # 发送请求 |
使用代理
在上面那段代码中,我们在请求过程中使用了代理,是为了防止频繁请求导致ip被封,代理功能可以自动切换代理,保证程序的正常运行。在测试过程中我们发现,该网站不会对ip进行封锁,所以代理可有可无。这里大致说一下代理功能是如何实现的。
代理功能使用的代理池是Github上的开源项目,它通过从代理平台抓取可用的代理ip存储到本地Redis中,需要使用代理时,即从本地Redis中取出。使用代理功能需要进行相应的配置。
1 | 安装并开启Redis服务器 |
在上述代码中,我们使用了捕捉异常的语句,因为在使用代理的过程中我们发现代理ip可能存在网络不稳定,传输有延时等问题。总的来说,使用代理的查询速度很慢,不想使用代理的话直接将proxy配置成本地的ip和端口即可。
多线程
在开发过程中,想过用多线程,但是效果不太理想(对并行编程不熟悉),后来想想对于查找准考证号这种问题可以根据实际情况灵活,可能有些人会大致记得自己的考场位于哪个区间之内,所以在项目中,提供了输入查询区间的接口。如果想提高查询速度,可以开启多个终端,每个终端输入不同的查询区间,这样就类似于开启了多进程(一般查询的时候开启10个终端,每个终端的考场区间为10,10分钟内可以查询到结果)。
使用教程
简单介绍一下该项目的文件结构,如图所示。
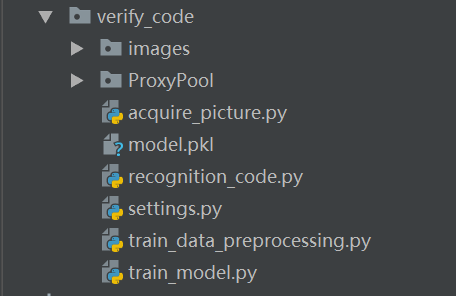
- images:主要用来存放验证码图片,images中包含多个目录,row_picture存放原始验证码,change_picture存 * 放灰度化、二值化处理后的验证码,train_data存放分割后的验证码
- proxypool:实现代理功能的相关代码
- acquire_picture.py:包含验证码获取、处理相关操作的代码
- model.pkl:存放识别模型
- recongnition_code.py:项目的执行入口,包含向服务器发送请求、代理等相关代码
- setting.py:项目相关的配置文件
- train_data_preprocessing.py:整合验证码获取和处理相关操作
- train_model.py:训练模型
该项目使用的大致流程如下(要求python版本不低于3.5,该项目在win10环境测试运行无误)。
1 | 安装相关依赖PIL、requests、numpyy、sklearn等 |
本文作者:光阴的故事
本文链接: verify-code.html/
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 CN 许可协议。转载请注明出处!

