摘要: 在之前的博客中介绍了三种对抗样本的生成算法,分别是FGSM、DeepFool和Universal Perturbation。这三种算法生成的对抗样本样本有一个共同的特点:其对抗性样例没有具体的目标,即我们无法控制目标模型对对抗性样例的分类结果。举例来说,如果我们构建了一个识别小动物的分类模型,现在我们需要对一张狗的照片生成其对抗性样例。先前的算法生成的对抗性样例只能达到让分类器分类错误的目的,比如说将其识别为一只鸡或者一只猫,分类结果是随机的、不可控的。更进一步,我们希望构建一种针对性更强的对抗性样例,比如说我们希望分类器对对抗性样例的分类结果只能是一只猫或者是由我们预先指定的一种小动物。本文介绍的JSMA算法可以达到这样一种目的。

文章概览
- 论文解读
- 攻击模型
- JSMA算法
- JSMA代码实现
论文解读
JSMA由Papernot等人提出,其论文发表于2016年S&P。论文的主要工作包括:从攻击者的目标和背景知识(或能力)两个方面来构建攻击模型、提出JSMA对抗样本生成算法、对对抗性扰动进行度量并构建防御机制。
攻击模型
分析攻击模型,主要从两个角度进行考虑:攻击者的目标和攻击者的背景知识。对于攻击者的目标而言,主要可以分为以下四类:
- Confidence reduction:减小输入分类的置信度,从而引入歧义
- Misclassification:将输出分类更改为与原始类不同的任何类
- Targeted misclassification:生成输入,强制输出分类为特定目标类
- Source/target misclassification:强制将特定输入的输出分类强制为特定目标类
对于攻击者的背景知识而言,主要可以分为以下五类:
- Training data and network architecture:最强大的背景知识,包含训练数据以及模型的结构和详细的参数信息
- Network architecture:了解目标模型的网络架构
- Training data:了解生成目标模型的训练数据
- Oracle:攻击者可以访问模型提供的接口,输入数据并获得反馈,并且可以观察到输入和输出的变化之间的关系
- Sample:攻击者可以访问模型提供的接口,输入数据并获得反馈,但是不能观察到输入和输出的变化之间的关系
针对不同的场景,攻击者将采用不同的攻击手法,这也是对抗样本领域研究的重点。
JSMA算法
JSMA算法的灵感来自于计算机视觉领域的显著图。简单来说,就是不同输入特征对分类器产生不同输出的影响程度不同。如果我们发现某些特征对应着分类器中某个特定的输出,我们可以通过在输入样本中增强这些特征来使得分类器产生指定类型的输出。JSMA算法主要包括三个过程:计算前向导数,计算对抗性显著图,添加扰动,以下给出具体解释。
所谓前向导数,其实是计算神经网络最后一层的每一个输出对输入的每个特征的偏导。以MNIST分类任务为例,输入的图片的特征数(即像素点)为784,神经网络的最后一层一般为10个输出(分别对应0-9分类权重),那对于每一个输出我们都要分别计算对784个输入特征的偏导,所以计算结束得到的前向导数的矩阵为(10,784)。前向导数标识了每个输入特征对于每个输出分类的影响程度,其计算过程也是采用链式法则。这里需要说明一下,前面讨论过的FGSM和DeepFool不同在计算梯度时,是通过对损失函数求导得到的,而JSMA中前向导数是通过对神经网络最后一层输出求导得到的。前向导数$\nabla \mathbf{F}(\mathbf{X})$具体计算过程如下所示,$j$表示对应的输出分类,$i$表示对应的输入特征。
$$
\nabla \mathbf{F}(\mathbf{X})=\frac{\partial \mathbf{F}(\mathbf{X})}{\partial \mathbf{X}}=\left[\frac{\partial \mathbf{F_j}(\mathbf{X})}{\partial x_i}\right]_{i \in 1 \ldots M, j \in 1 . . N}
$$
$$
\begin{aligned} \frac{\partial \mathbf{F_j}(\mathbf{X})}{\partial x_i}=&\left(\mathbf{W}_{n+1, j} \cdot \frac{\partial \mathbf{H_n}}{\partial x_i}\right) \times \frac{\partial f_{n+1, j}}{\partial x_i}\left(\mathbf{W}_{n+1, j} \cdot \mathbf{H_n}+b_{n+1, j}\right) \end{aligned}
$$
通过得到的前向导数,我们可以计算其对抗性显著图,即对分类器特定输出影响程度最大的输入。首先,根据扰动方式的不同(正向扰动和反向扰动),作者提出了两种计算对抗性显著图的方式,即:
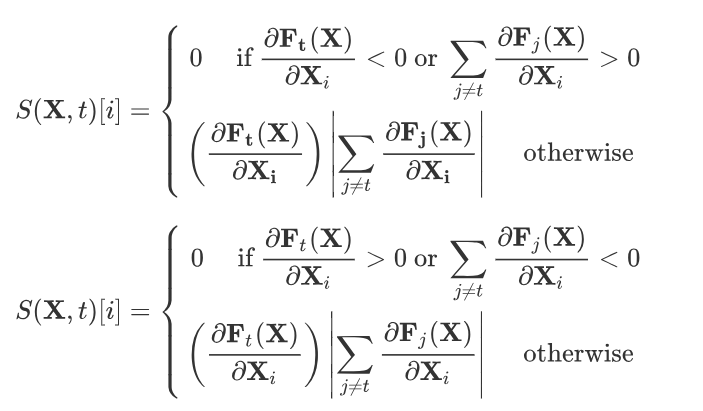
但是在文章中第四部分的应用中作者发现,找到单个满足要求的特征很困难,所以作者提出了另一种解决方案,通过对抗性显著图寻找对分类器特定输出影响程度最大的输入特征对,即每次计算得到两个特征
$$
\arg \max _{\left(p_1, p_2\right)}\left(\sum_{i=p_1, p_2} \frac{\partial \mathbf{F_t}(\mathbf{X})}{\partial \mathbf{X_i}}\right) \times\left|\sum_{i=p_1, p_2} \sum_{j \neq t} \frac{\partial \mathbf{F_j}(\mathbf{X})}{\partial \mathbf{X_i}}\right|
$$
具体的计算过程可以参考文章中的算法3。(注:根据扰动方式的不同,这种算法也有两种计算对抗性显著图的方式)
根据对抗性显著图所得到的特征,可以对其添加扰动。扰动方式包括正向扰动和反向扰动($+\theta$或$-\theta$)。如果添加的扰动不足以使分类结果发生转变,我们利用扰动后的样本可以重复上述过程(计算前向导数->计算对抗性显著图->添加扰动)。这个过程需要注意两点
- 扰动过程的重复次数需要被约束,即修改的特征数有限
- 一旦添加扰动后,该特征达到临界值,那么该特征不再参与扰动过程
JSMA算法实现
同样,为了便于理解,这里给出相关代码段(与之前的数据集和网络模型一致)。所有的代码基于python实现,使用的深度学习框架为pytorch,更加完整的算法实现参见我的github。(注:本文JSMA算法实现部分代码参考了DEEPSEC)
网络模型
1
2
3
4
5
6
7
8
9
10
11class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28*28, 300)
self.fc2 = nn.Linear(300, 100)
self.fc3 = nn.Linear(100, 10)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x数据集(这里只给出测试集的数据定义)
1
2
3
4
5# 定义数据转换格式
mnist_transform = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x : x.resize_(28*28))])
# 导入数据,定义数据接口
testdata = torchvision.datasets.MNIST(root="./mnist", train=False, download=True, transform=mnist_transform)
testloader = torch.utils.data.DataLoader(testdata, batch_size=256, shuffle=True, num_workers=0)
对于前向导数,如果根据链式法则一层层的推导,计算过程十分复杂。但是在深度学习框架中,对于反向传播过程的梯度的计算都已经封装好,我们只需要简单的调用即可,所以前向导数的计算过程十分简单,如下所示
1 | def compute_jacobian(model, input): |
计算对抗性显著图的过程也较为简单,一般根据算法的描述一步步实现并不难。但是在该过程中存在一个问题,我们每次需要找到满足要求的一对特征,那组合的方式一共有784*783种,如果采用普通的循环来实现计算代价很大。参考了DEEPSEC的代码,我发现他们将这个问题巧妙的转化为矩阵求解的问题,大大缩短了计算时间。
1 | def saliency_map(jacobian, target_index, increasing, search_space, nb_features): |
算法其余的实现可以参考我的gihub。代码完成后进行了一些测试,选取原始样本0,目标分类结果分别为0-9。我们采用JSMA算法对其添加噪声,得到的结果如下所示。


我们将这些图片分别丢入原始分类器中,分类结果与我们的目标全都一致。由此看来,一般情况下,JSMA算法的效果还是很不错的。
本文作者:光阴的故事
本文链接: 对抗样本生成系列:JSMA目标扰动.html/
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 CN 许可协议。转载请注明出处!

